
Neuroscience FoMO: Foraging across Many Options
21 February 2025
An interview with Dr Laura Grima, Janelia Research Campus.
When studying how animals, including humans, make decisions, neuroscientists often use experiments with two options. In many ways, choosing between two things is one of the most fundamental forms of decision-making. But while this approach has given us great insight into how the brain works, it doesn’t always reflect real life. When we make a decision, there are usually many options to choose from, many courses of action we could take, and many other factors to take into account.
To study decision-making in a more natural environment, Dr Laura Grima, from Janelia Research Campus, USA, is using a different approach. She studies mice in a large arena, with multiple places where they can forage water. Not all the locations with water are equal - some have frequent water, others infrequent. Called ‘Foraging across Many Options’ (FoMO), she studies the behaviour of mice in the arena - specifically how they decide where to go and which option to choose.
Dr Grima recently spoke at the SWC as an awardee of the Emerging Neuroscientists Seminar Series. She described her work with the FoMO setup, and the computational model – AQUA – she and her collaborators developed which describes the animal’s behaviour and choices in the arena. Here, she discussed her findings and the difficulties of science when trying to capture the complexity of life.
When you were thinking about designing a new paradigm for your foraging experiments with multiple options, how did you decide on what to go for? What gaps were you trying to address with your set-up?
There is this assumption that if something works in a two-option context, then it should also work when you have lots of options. But that is a big assumption. That is one aspect of what we wanted to test.
For example, do the algorithms that have been developed to describe decision-making - and work really well when you have two options - work well when you have more than two options? The answer is no, not always.
One other problem with the two-option context is you might not be able to identify strategies that a human or a mouse might be using. For example, always going left - that can be a strategy. Sometimes it's hard to tell apart that strategy from a preference for one option. If you have many options, then it allows you to start distinguishing these things.
We were also really interested in how animals initially learn to make decisions across many options. But you really only get one shot at this; the next time the mouse does the task it already knows something about the environment. There is a very limited time window and very limited data to then understand these processes. So, if you then have strategies that are separated out by the fact that there are many more options to visit, that really helps.
A final really important aspect of our set-up is that the options are spread over a (relatively) large distance, in an arena a couple of metres long. A key part of theories about foraging is this idea that animals take into account how far they have to move, or ‘travel’, between options when deciding where to go next. But there aren’t many studies that actually test this in the lab using real, spatial distances between options. And so exactly how animals integrate travel into their decisions whilst foraging – particularly when they’re in a new environment – is less known.
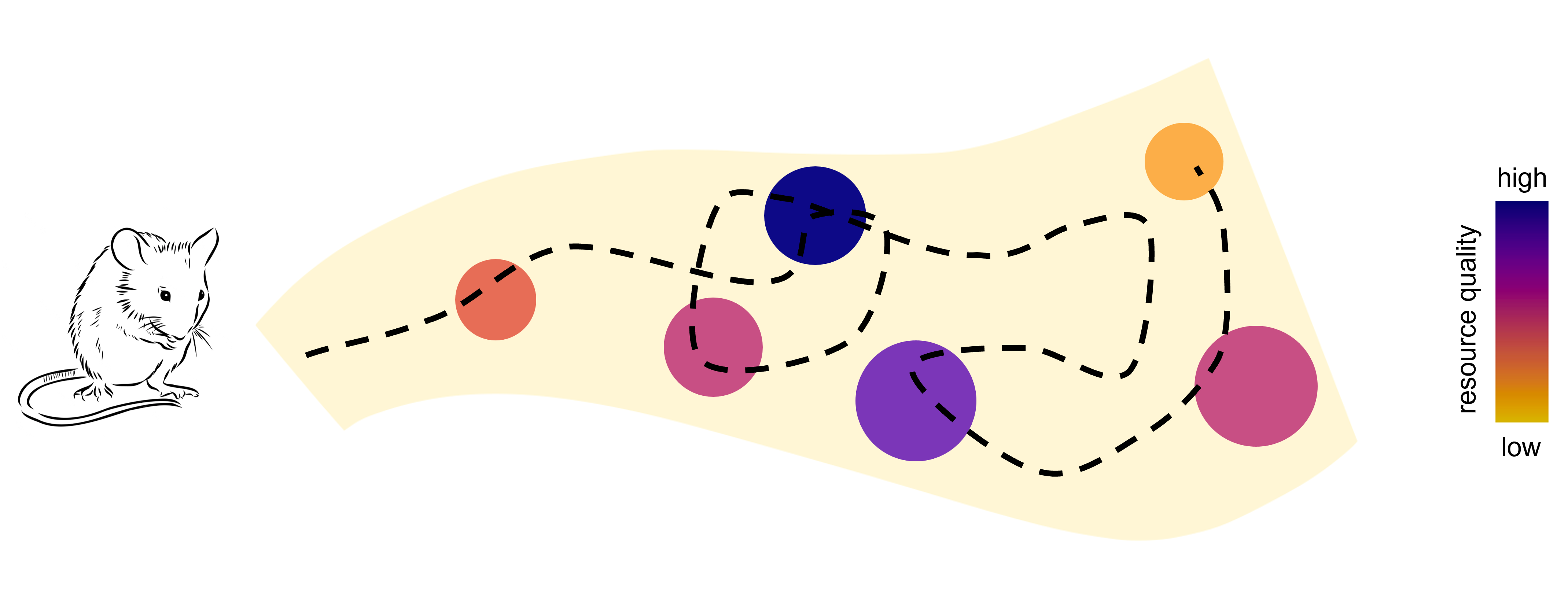
The animals settled into near-optimal behaviour – getting maximum water from the arena - within tens of minutes. This was more quickly than previous studies have shown - were you surprised? And why do you think they did this so fast?
I think there are a lot of ideas that to get close to optimality - in this case, learning to transition between spatially distributed options in a way that yields the most reward possible - usually would take a very long time. You’d need to train a mouse, and it would need lots of practice.
But by allowing the mice to be in a more natural context, where they can run around freely, where they can choose what they like when they like - I think that is the crux of why they can then learn so quickly. In essence, they are solving the sort of problem they might encounter out in the wild. And in the wild, it’s to their advantage to be able to quickly learn how to get the resources they need in different sorts of environments.
You found that mice did take distance into account when deciding where to go next, but they didn't make an obvious attempt to minimise their path lengths or travel time. What do you think that reveals about how they make decisions? Do you think that other spatial factors, like line of sight, or the possibility of threats, might be important?
Yes - I think those other factors are really interesting. It’s not a maze – there are no obstacles, this is an open arena. So here the mice can really express themselves through their trajectories.
In the future, we are interested in thinking about trying to use that as a way of thinking more about when they're making a decision. What are they integrating in order to generate these trajectories?
In our hands in this experiment, it seems like running around is not necessarily a cost. I think part of that is because the animals are simultaneously exploring the arena as well as doing our ‘task’ of choosing between options. There is some value to exploration which isn’t taken into account in most classical foraging models.
More generally, we should always be questioning what we think of as the mouse’s ‘objective function’ – in other words, what its goals are. We can do this by taking the perspective of the animal, which is integrating many other sources of costs and benefits even if we don’t explicitly manipulate them in our lab tasks.
For example, in experiments like this, we might think that the animal should optimise for how many rewards they get across the different options. But actually, the mouse is thinking well hey, I should know what's over there. And I should double-check there are no predators anywhere.
This has intrinsic value to the animal as well.
In the wild, mice might travel for miles. The terrain is bumpy, and there is a risk of predators. So, the costs of travelling are going to be different. There are a lot of other factors that we do not take into account, but this was the starting point for us to try and move towards a better understanding of what influences animal decision-making and how this might be implemented in the brain.
AQUA, the algorithm you have developed that describes decision-making, incorporates insights from foraging theory and reinforcement learning. Can you talk a little bit about the advantages of AQUA over traditional foraging models like the marginal value theorem (MVT)?
MVT is a model originally developed by behavioural ecologists to solve a specific sort of foraging problem. It basically determines that the best time to leave a patch of resources that is being depleted, is the moment its reward rate becomes lower than the average of elsewhere in the environment.
MVT is very influential both in behavioural ecology and neuroscience. It’s one way of simplifying the complex problem of how animals make patch leaving foraging decisions. Although AQUA doesn’t use this exact calculation, it is inspired by an important insight from MVT: that foraging decisions can be thought of ‘stay or leave’ this option.
The downside of MVT is that it doesn't tell you how you learn these variables to make these decisions, or which option to choose next.
Reinforcement learning (RL), which AQUA is based on, on the other hand, is one method for parameterising exactly what you should update when making decisions or choosing actions. So in the case of six options, how do I update my information about them based on my previous experience? And therefore how do I learn about them? There are different ways of doing this in RL models – in the case of AQUA for example, it basically keeps a running track of reward for each option to give an estimate of how good each one is. And so another important variable is, how much should I update my estimate of the quality of an option each time I choose it?
In this way, it's very different from MVT, which is more like a clever rule of thumb. AQUA (and other RL models) aim to formalise exactly what parameters go into learning and decision-making.

What are your key findings so far using FoMO and AQUA?
Putting mice in the FoMO arena revealed to us that they can learn about many options very quickly, and they use a ‘matching’ strategy to do so. Basically, they learn to choose each option in proportion to how relatively rewarding it has been.
AQUA gave us insight as to how the mice might be doing this sort of rapid learning. Two key features made the AQUA model successful in replicating mouse behaviour. The first is framing the decision as 'stay or leave–and if leave, where next?’.
This reflects how mice are sensitive to the fact that they have to transition between options by moving through space. In other words, they care where they’re currently at. The second is a variable learning rate across all options. This allowed the model to learn very quickly early in the session but then settle into a matching strategy later in the session, exactly as the mice do. We feel confident that the model has captured some of the core processes driving mice learning and decision-making in this kind of foraging environment; the behaviour of AQUA looks very similar to mouse behaviour in a number of fundamental aspects.
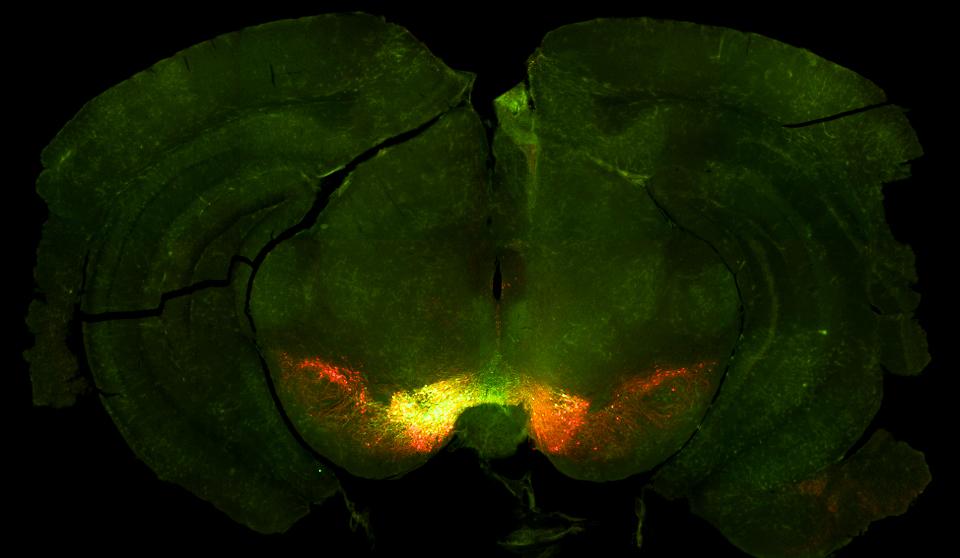
Whilst mice foraged in FoMO, we used a method called fibre photometry to record dopamine levels in two parts of a region of the brain called the striatum. There’s a huge literature on the role of dopamine in learning about reward, but these signals are not often studied in this sort of context, particularly so early in learning. We found that dopamine in one part of the striatum, the nucleus accumbens core (NAcC), looked like that variable, global learning rate that we needed in AQUA.
This suggests that NAcC dopamine plays a unique role in helping mice quickly adapt to multiple different options in large environments.
How do you envision further developments of the AQUA algorithm?
We developed AQUA to understand the choices that mice made in FoMO in terms of which option they’re likely to sample next based on where they currently are. It does this very well, but it doesn’t fully account for all the other behaviour that’s also going on. For example, we have some evidence that mice might be structuring their behaviour beyond the specific transitions they make from one option to the next, making longer sequences of choices. And when they make their choices, they sometimes generate very complex trajectories moving from one reward spout to another.
AQUA currently doesn’t generate these sorts of behavioural structures and we’ve been thinking a bit about how to account for these other important aspects. Similarly, right now AQUA has this representation of the six options. What if you have 100 options? A grouping together, or hierarchical map of the options, might be necessary for being able to learn efficiently in even more complex environments.
The cool thing about having a model like AQUA is that it allowed us to make predictions about what is happening in the brain with dopamine. This closed-loop approach of understanding behaviour through modelling, and then using the model to make predictions that we can test either in the brain, or by going back and manipulating behaviour, is very satisfying and allows us to test specific hypotheses. Further developments of AQUA are crucial for this, but we must remember to be inspired by the behaviour - by what the mice actually do - first and foremost.
How generalisable do you think your findings are to other species, including humans? Do you think that there are similar neural mechanisms to govern decision-making across different animals?
I think the very simplistic but straightforward answer is yes. Part of the appeal of studying foraging behaviours is that it’s something that other animals, including humans, do as well. So in principle, we might expect some of the fundamental neural mechanisms driving this sort of decision-making to overlap, and there are lots of great labs working on foraging decisions in humans for example. Certainly, others have found that a changing learning rate is useful both in other contexts, but also in other species. And even in machine learning it's commonly used as well.
However, there will also be differences across species too, for example in how costly travel is. We’ve thrown around this idea in the lab of having a human version of this task where people go around something like a football field and there are places where they can get intermittent rewards. These kinds of direct comparisons are important for identifying what we can and can’t generalise across species, and will help us identify cross-species algorithms for these sorts of fundamental behaviours, so it’s something I’d like to do more of in the future.
Finally, the nice thing about AQUA is that the kind of formulation that we based it on - Q-Learning – means that it also applies to other environment dynamics or types of decisions as well. It doesn't have to be foraging. For example, it does a good job of making decisions in a two-armed bandit-style environment. You can imagine that something that works well in different sorts of environments should also be beneficial across species.
What practical applications do you think your findings might have in clinical settings?
A lot of neuroscientists are interested in decision-making in part because there are a number of disorders that can be characterised as when decision-making ‘goes wrong’. For example, most people know of some subtypes of ADHD as involving difficulties in being able to stay on task.
In some ways, this is analogous to how our mice make decisions early in learning – exploring all of the options. And indeed sometimes that can be advantageous.
But at some point, it’s better to settle into a single strategy or approach and perhaps that takes longer or is disrupted in ADHD. There are studies that have linked aberrant learning rates to ADHD, for example. Here we have one possible candidate neural mechanism of this, at the level of dopamine.
More generally, studying more ‘realistic’ types of decisions in both rodents and humans might give us better access to the translational potential of these kinds of experiments. In other words: if it takes weeks or months to train a mouse to make a decision, can we assume that the neural mechanisms underlying those decisions are the same as when a human makes a similar choice in a matter of seconds or minutes? Because of this I think there’s a lot of potential in the study of more natural decision-making in helping us translate our rodent experiments to humans.
What do you see is the next big question in studying foraging?
For me personally, in the shorter term I'm thinking about how wider brain circuits contribute to foraging behaviour. The focus of my current work has been the role of dopamine in foraging decisions, but I have recordings in hippocampus as well. The hippocampus has been studied in the context of spatial and relational maps, so it seems like a critical area for these types of spatially-driven foraging behaviours. How do those regions interact? Does dopamine shape hippocampal activity when learning to forage?
More broadly, I think an important point to make is that foraging itself isn’t a question but rather a framework of defined behaviours. It's a way of thinking about the kinds of other cognitions or processes that neuroscientists are generally interested in, like decision-making and learning.
So I think the big question is how can we best utilise this framework, whilst being open to questioning our own assumptions as a field.
And I think the really big question is how do we philosophically, as neuroscientists, learn to deal with the complexity of real behaviour? Thankfully there already are a lot of very clever people thinking about this from many different angles, so I’m excited about where this might take us in the future.

About Dr Grima
Laura Grima is a postdoctoral associate in the Dudman Lab at the Janelia Research Campus. Prior to this position, she completed both a Master’s and DPhil (PhD) at the University of Oxford, with her PhD focusing on the role of mesolimbic dopamine and activity at striatal receptor subtypes on goal-directed action. She became interested in foraging behaviours during a brief postdoctoral position in Oxford, where she found that slow changes in ventral striatal dopamine levels reflected environment quality in trained mice making decisions in a novel operant chamber-based foraging task. In 2019 she moved to Janelia to study the role of dopamine in naïve mice making foraging decisions in large spatial environments.

